


13.07.2019 - 21:50
|
Actualització: 14.07.2019 - 14:28
Tres membres del Grup d’Investigació en Psicolingüística de la Universitat Rovira i Virgili han desenvolupat una aplicació per a mesurar quantes paraules saben els parlants catalans. Un dels impulsors, Roger Boada, ha confirmat a VilaWeb que a hores d’ara ja hi havien participat més de 183.000 persones. L’aplicació, que té forma de joc, presenta a l’atzar mots existents en català i mots inventats. El jugador només ha de respondre si la paraula que li surt a la pantalla existeix o no. El joc va adreçat a tots els parlants, de qualsevol dialecte, i tant a nadius com a aprenents del català. S’hi pot accedir amb ordinadors personals i amb dispositius mòbils.
Una partida breu, estimulant i amb opcions de millora
La partida dura cinc minuts i tan bon punt s’acaba ja se’n poden saber els resultats, de manera que el jugador pot tenir una estimació del percentatge de paraules que sap i comparar el seu nivell de coneixement amb el de la resta de la població.
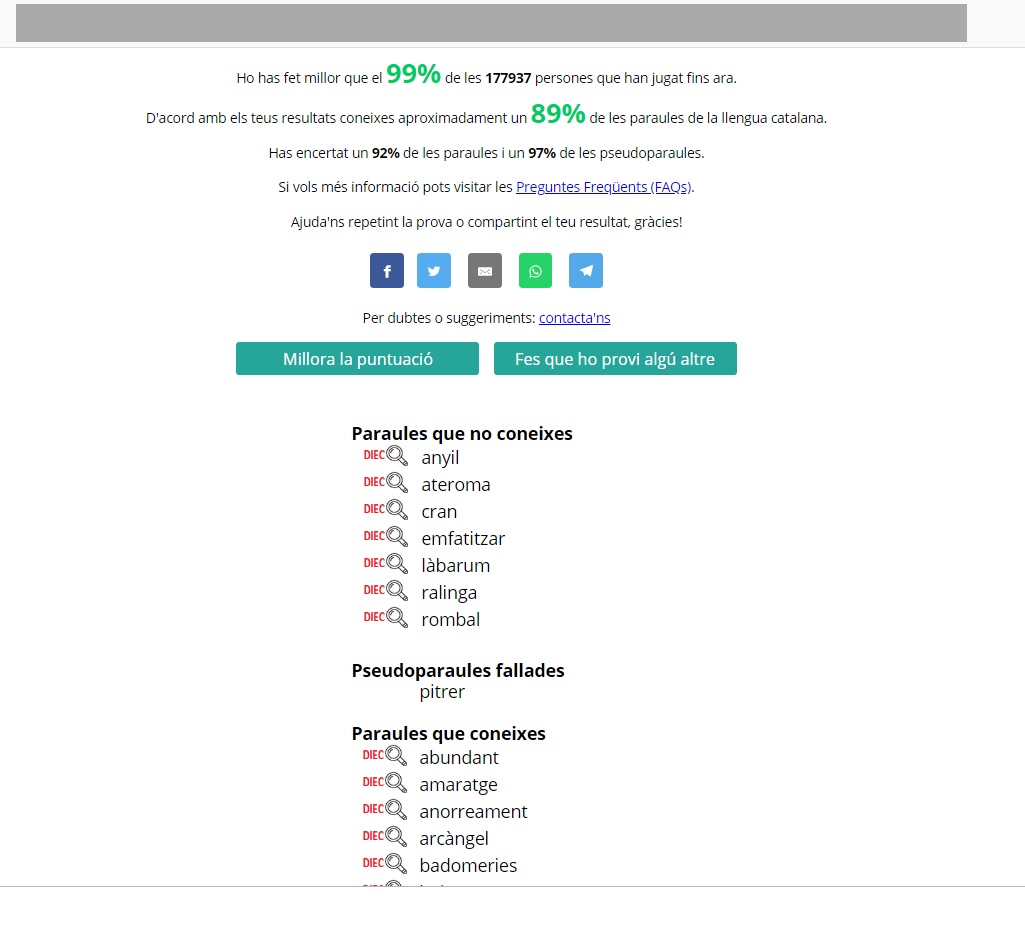
Gràcies al joc, hom pot aprendre noves paraules, perquè quan s’acaba la partida l’aplicació permet de consultar al diccionari de l’Institut d’Estudis Catalans (DIEC2) les que s’han fallat. El jugador pot fer tantes partides com vulgui per provar de millorar el resultat. A més, si comparteix la puntuació obtinguda a les xarxes socials, pot desafiar amics, familiars i coneguts. Així es pot escatir quantes paraules sap cadascú i contribuir a difondre el projecte.
Un estudi de gran magnitud, homologable i amb moltes possibilitats futures
Amb les respostes obtingudes fins ara (més de 183.000) ja s’ha convertit en l’estudi psicolingüístic de més abast en llengua catalana. És equiparable a alguns de semblants que s’han fet en llengües com ara l’anglès, l’espanyol i el neerlandès, en què s’ha superat la xifra de 200.000 participants. ‘Aquesta és la xifra que voldríem superar, per bé que d’entrada ens havíem marcat l’objectiu de 50.000’, diu Boada.
La informació aplegada es desarà de manera anònima, únicament amb finalitats científiques. De primer, el resultat s’emprarà per a elaborar un article centrat en els aspectes psicolingüístics, que és l’àmbit d’estudi del grup. Tanmateix, la informació farà molta més llevada. Servirà per a construir un gran banc de dades amb què s’estudiaran diversos aspectes relacionats amb la llengua catalana. Per exemple, es podrà saber fins a quin punt l’edat, el nivell d’estudis, el sexe i la competència lingüística afecten l’amplitud del vocabulari dels parlants. També es podrà determinar el percentatge de parlants que sap cada mot i això en serà un indicador del grau de dificultat.
Així mateix, en el futur es podran desenvolupar eines com ara proves estandarditzades de vocabulari que seran útils en l’àmbit de l’ensenyament del català com a segona llengua, car permetran d’avaluar l’evolució dels aprenents. També es podran establir mesuraments objectius sobre la complexitat dels texts en llengua catalana i això és cabdal a l’hora d’elaborar materials docents per a adequar-los al nivell dels alumnes. Finalment, gràcies al fet de disposar dels temps de resposta mitjans de cada paraula es podrà estudiar quines característiques afecten el processament i l’emmagatzematge de mots i significats en la ment humana.
Els impulsors d’aquest estudi són els investigadors Roger Boada, Marc Guasch i Pilar Ferre, del Grup d’Investigació en Psicolingüística de la URV. Per a fer aquest estudi, han col·laborat amb Jon Andoni Duñabeitia, director del Centre de Ciència Cognitiva (C3) de la Universitat de Nebrija, que ja havia desenvolupat iniciatives similars en més llengües.

40.000 paraules de debò i 30.000 de mentida
‘Cada partida conté 120 estímuls, dels quals 84 són paraules i 36 són pseudo-paraules, és a dir, cadenes de lletres que segueixen les normes del català però que no tenen significat’, explica Boada.
De mots ‘de debò’ n’hi ha 40.777, que s’han extret partint de les 70.000 entrades del DIEC2, però seleccionant-ne els que havien aparegut, pel cap baix, una vegada en quatre anys en els subtítols de totes les cadenes de la Corporació Catalana de Mitjans Audiovisuals (CCMA). En total, el corpus extret dels subtítols de la CCMA tenia 278 milions de mots i el Grup de Recerca en Psicolingüística ja el va publicar. En la tria que s’ha fet per a l’aplicació s’han evitat formes derivades i verbs conjugats.
Com i fins quan s’hi pot participar?
Per participar en aquest projecte tan solament cal entrar en aquesta web. Els impulsors expliquen a VilaWeb que la deixaran oberta perquè la gent hi entri i hi jugui, però a començament de setembre aplegaran les dades que tinguin, les analitzaran i en publicaran els resultats en una revista científica internacional.
Com més participants hi hagi, millor, perquè les conclusions de l’estudi seran més acurades. ‘Per tant –diu Roger Boada–, petits i grans, aprenents o nadius, parlin la variant que parlin, tothom pot posar a prova el seu coneixement de la llengua, fer-ne la màxima difusió possible i col·laborar amb la ciència.’
