


08.08.2025 - 21:40
Com més va, més habitual és de fer servir ChatGPT en el dia a dia. La gent no tan sols li dóna instruccions per a fer accions concretes, sinó que també hi manté llargues converses en què li explica molts aspectes de la seva vida quotidiana. Les semblances aparents amb una conversa de WhatsApp pot donar una falsa aparença d’intimitat, però cal tenir molt clar que qui tenim al davant no és pas un amic, sinó una eina desenvolupada per l’empresa nord-americana OpenAI que fa servir aquestes converses per millorar els seus models d’intel·ligència artificial. Així doncs, fins a quin punt són confidencials les coses que diem a ChatGPT?
Tenint en compte allò que diu la política de privadesa d’OpenAI, cal distingir entre les dades del compte –com ara el nom, les credencials, o la informació de pagament–, les dades automàtiques –com la IP, el navegador o el dispositiu amb què hi accedim– i tot aquell contingut que li aportem en una conversa, bé en forma de text, d’imatges, d’àudio o dels fitxers que hi adjuntem. Són aquestes darreres les que més preocupen, perquè hi podem donar detalls personals d’una manera més àmplia. No hi ha cap acotació, és tot allò que pugui sorgir en una conversa o que nosaltres activament puguem voler-li dir en un moment determinat.
OpenAI, com tantes altres empreses d’intel·ligència artificial, fa servir les dades d’ús dels usuaris per millorar els seus models, per fer-los més precisos. Això vol dir que tot allò que un particular diu a ChatGPT o a serveis com DALL·E, Codex o Sora pot ser reaprofitat per l’empresa. OpenAI diu que pren mesures per reduir la quantitat d’informació personal que hi ha a les converses abans d’entrenar els models, tot i que se li poden escapar les dades menys explícites. A més, cal tenir en compte que no fa servir un xifratge d’extrem a extrem, de manera que les dades en brut són enregistrades als servidors d’OpenAI abans no s’anonimitzen. No és, doncs, un sistema infal·lible, i de fet OpenAI mateix recomana als usuaris que no donem detalls gaire personals en les nostres converses.
Un altre indicatiu del risc de privadesa que implica l’ús de les nostres converses per a entrenar els models és que, per atreure les empreses perquè facin servir ChatGPT en la pràctica professional, OpenAI exclou de l’entrenament dels models totes les interaccions fetes als comptes amb les subscripcions empresarials ChatGPT Team, ChatGPT Enterprise, ChatGPT Edu, i amb la plataforma API. A més, es pot definir durant quant de temps s’emmagatzemen les dades generades i OpenAI es compromet a esborrar allò que hom li demani en un termini de trenta dies, sempre que no estigui obligat legalment a conservar-ho.
Com podem fer que no entreni els models amb les nostres dades?
Més enllà dels comptes d’empresa, OpenAI també ofereix a la resta d’usuaris la possibilitat de marcar que les dades no poden ser utilitzades per a entrenar els seus models d’intel·ligència artificial. Per a fer-ho, n’hi ha prou d’anar al portal de privadesa d’OpenAI i demanar-ho clicant a “Do not train on my content”. Ens demanarà de confirmar l’opció i indicar des d’on fem servir el compte. Tot seguit la petició ja s’haurà registrat.
Amb això, ens assegurem que les converses futures no siguin utilitzades per entrenar els seus models, però no les passades. Gràcies al reglament europeu de protecció de dades, també li podem demanar que esborri certa informació personal passada, però cal especificar-li què volem que esborri i per què. A més, OpenAI es reserva el dret de jutjar la sol·licitud “equilibrant els drets de privadesa i protecció de dades amb altres drets, com ara la llibertat d’expressió i d’informació, d’acord amb la legislació aplicable”.
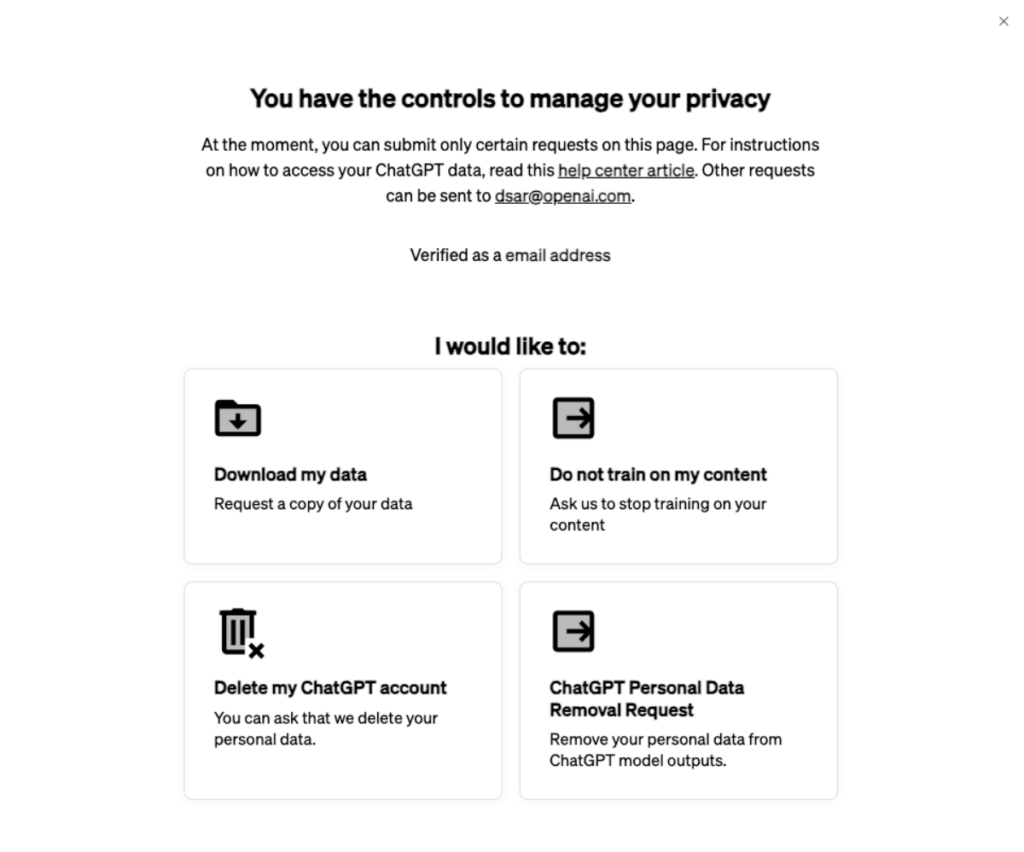
A banda, al portal de privadesa també podem demanar que ens enviï una còpia de les dades associades al nostre usuari que hi ha als servidors d’OpenAI, o bé que esborri el nostre compte de ChatGPT.
ChatGPT té “memòria” per a personalitzar el seu comportament
Més enllà de l’entrenament dels models, ChatGPT també desa certes informacions nostres per a personalitzar les interaccions amb nosaltres. Ho anomena la seva “memòria“, una funció que li permet de recordar el nostre nom, els nostres interessos i l’estil de resposta que preferim. La memòria es pot activar o desactivar, i és personalitzable: es pot demanar que recordi alguna cosa o esborrar una informació en concret que no volem que retingui. Cal anar al menú de configuració, i, tot seguit, a la pestanya de personalització.
Gràcies a aquest sistema, ChatGPT manté una coherència a cada conversa que tingui, sense necessitat de dir-li cada vegada com ha de respondre. Val a dir que la capacitat d’emmagatzematge és limitada, i a partir d’un cert moment avisa que cal esborrar alguns dels records perquè en pugui integrar de nous.
Ara, la memòria serveix solament per a personalitzar l’experiència d’ús, i no es fa servir per millorar els models d’intel·ligència artificial. Dit de manera àmplia, la memòria és útil per a millorar la interacció de manera individual, i l’entrenament dels models fa que millori ChatGPT en conjunt.
Les converses poden ser utilitzades judicialment?
Les converses amb ChatGPT es guarden xifrades als servidors d’OpenAI, però són desxifrades quan es necessiten per a millorar els models. De la mateixa manera, també poden ser desxifrades en cas de rebre un requeriment judicial. Recentment, el director executiu d’Open AI, Sam Altman, va avisar en un pòdcast que allò que s’explica a ChatGPT no té la protecció legal equivalent a la de professionals com ara metges, advocats o psicòlegs, que han de guardar el secret de confidencialitat dels ciutadans que tracten.
En cas que un jutge ho demani, OpenAI té l’obligació legal de lliurar les dades que guardi al seu servidor, incloent-hi converses i metadades associades a un compte en concret. Arribat el cas, es podria arribar a considerar una conversa com una prova en un judici. Actualment, OpenAI és enmig d’una batalla judicial amb l’empresa editora de The New York Times, que l’acusa d’haver vulnerat els seus drets d’autor per haver entrenat els models d’intel·ligència artificial propis amb articles seus sense permís. Arran d’això, una jutgessa federal va ordenar de conservar tots aquells registres generats per ChatGPT –inclosos aquells que la política de privadesa es comprometia a esborrar– fins que no s’hagi aclarit el cas.
OpenAI hi ha presentat un recurs en contra perquè aquesta ordre deixa l’empresa en una situació compromesa tant davant els seus usuaris, als quals havia promès unes condicions en la política de privadesa que ara ha hagut de canviar, com davant les exigències del reglament europeu de protecció de dades. Arran d’això, Altman reclamava en aquesta mateixa entrevista que es fes una llei urgentment per a establir uns estàndards de privadesa adequats per a la intel·ligència artificial, si més no equivalents als que tenen els professionals a qui es reconeix el secret professional.
Per tot plegat, és clar que les converses amb ChatGPT no són confidencials, per molt que pugui transmetre aquesta aparença. Són desades als servidors d’OpenAI i els seus treballadors les poden desxifrar tant per a entrenar els models d’intel·ligència artificial com per a posar-les a disposició de la justícia. Malgrat que es pugui limitar en certa manera l’ús que OpenAI en pot fer, no és possible d’aconseguir una seguretat total dels missatges.


